Sentieon
Sentieon 中文手册
Sentieon 中文手册(上册)
Sentieon 中文手册(下册)
Sentieon 软件应用教程
Sentieon | 联合Dell、AMD开发基因组大数据分析加速方案
Sentieon | 应用教程: 利用Sentieon Python API引擎为自研算法加速
Sentieon | 应用教程: 关于读段组的建议
Sentieon | 应用教程: 使用DNAscope对HiFi长读长数据进行胚系变异检测分析
Sentieon | 应用教程: TNscope® 使用机器学习模型进行有匹配正常样本的体细胞变异发现
Sentieon | 应用教程: CCDG使用Sentieon®的功能等效流程
Sentieon | 应用教程: 利用共识功能去除PCR重复
Sentieon | 应用教程: 适用于PacBio HiFi和Oxford Nanopore长读长测序数据的结构变异检测
Sentieon | 应用教程: 使用 Sentieon进行大型基因组重测序分析
Sentieon | 应用教程: 体细胞SNP/Indel变异检测
Sentieon | 应用教程: DNAscope使用机器学习模型进行胚系变异调用
Sentieon | 应用教程: 唯一分子标识符(UMI)
Sentieon | 应用教程: Sentieon分布模式
Sentieon | 应用教程:使用CNVscope进行CNV检测分析
Sentieon发布核心家系(trio)基因分析最佳实践方案
Sentieon推出Segdup-caller:针对片段重复区域的专用精准变异检测工具
Sentieon-cli | DNAscope WES 流程单条命令版本详解
Sentieon | DNAscope 核心家系(trio) WES 分析全流程详解
Sentieon | DNAscope Hybrid长短读长混合分析流程详解及评测
Sentieon | 基于Illumina WGS数据的高精度、低成本的泛基因组分析方案
Sentieon软件版本更新
Sentieon | 发布V202503.01版本
Sentieon | 发布V202503.02版本
Sentieon | 发布V202503.03版本
Sentieon软件快速入门指南
Sentieon 软件模块总述
Sentieon 特色流程 - DNAscope
Sentieon | DNAscope Illumina 流程
sentieon | DNAscope Complete Genomics 流程
Sentieon | DNAscope LongRead PacBio 流程
Sentieon | DNAscope Ultima Genomics 流程
Sentieon | DNAscope Element Bio 流程
Sentieon | DNAscope LongRead Nanopore 流程
Sentieon混合分析流程 - DNAscope Hybrid
Sentieon推出混合型短读长和长读长变异检测DNAscope Hybrid流程(上)
Sentieon推出混合型短读长和长读长变异检测DNAscope Hybrid流程(下)
毅硕Sentieon | 泛基因组分析流程详解
毅硕Sentieon | RNA-seq 变异检测全流程详解
毅硕Sentieon | 物种全基因组(WGS)分析流程
毅硕Sentieon | 植物全基因组(WGS)分析流程
毅硕Sentieon | 小麦(Triticum aestivum)全基因组WGS分析流程
毅硕Sentieon | 水稻(Oryza sativa)全基因组WGS分析流程
毅硕Sentieon | 拟南芥(Arabidopsis thaliana)全基因组WGS分析流程
毅硕Sentieon | 马铃薯(Solanum tuberosum)全基因组WGS分析流程
毅硕Sentieon | 巨桉(Eucalyptus grandis)全基因组WGS分析流程
毅硕Sentieon | 向日葵(Helianthus annuus)全基因组WGS分析流程
毅硕Sentieon | 野草莓(Fragaria vesca)全基因组WGS分析流程
毅硕Sentieon | 银杏(Ginkgo biloba)全基因组WGS分析流程
毅硕Sentieon | 大豆(Glycine max)全基因组WGS分析流程
毅硕Sentieon | 陆地棉(Gossypium hirsutum)全基因组WGS分析流程
毅硕Sentieon | 胡桃(Juglans regia)全基因组WGS分析流程
毅硕Sentieon | 苹果(Malus domestica)全基因组WGS分析流程
毅硕Sentieon | 香蕉(musa acuminata)全基因组WGS分析流程
毅硕Sentieon | 罂粟(Papaver somniferum)全基因组WGS分析流程
毅硕Sentieon | 开心果(Pistacia vera)全基因组WGS分析流程
毅硕Sentieon | 毛果杨(Populus trichocarpa)全基因组WGS分析流程
毅硕Sentieon | 动物全基因组(WGS)分析流程
毅硕Sentieon | 猪(sus scrofa)全基因组WGS分析流程
毅硕Sentieon | 鸡(Gallus gallus)全基因组WGS分析流程
毅硕Sentieon | 家鼠(Mus musculus)全基因组WGS分析流程
毅硕Sentieon | 家犬(canis lupus familiaris)全基因组WGS分析流程
毅硕Sentieon | 东方蜜蜂(Apis cerana)全基因组WGS分析流程
毅硕Sentieon | 电鳗(Electrophorus electricus)全基因组WGS分析流程
毅硕Sentieon | 红隼(Falco tinnunculus)全基因组WGS分析流程
毅硕Sentieon | 家猫(Felis catus)全基因组WGS分析流程
毅硕Sentieon | 尼罗罗非鱼(Oreochromis niloticus)全基因组WGS分析流程
毅硕Sentieon | 狮子(Panthera leo)全基因组WGS分析流程
毅硕Sentieon | 东北虎(panthera tigris altaica)全基因组WGS分析流程
毅硕Sentieon | 黑猩猩(pan troglodytes)全基因组WGS分析流程
毅硕Sentieon | 中国鳖(pelodiscus sinensis)全基因组WGS分析流程
毅硕Sentieon | 褐家鼠(rattus norvegicus)全基因组WGS分析流程
毅硕Sentieon | 家牛(Bos taurus)全基因WGS分析流程
毅硕Sentieon | 虎河豚(takifugu rubripes)全基因WGS分析流程
毅硕Sentieon | 人类(Homo sapiens)全基因组WGS分析流程
毅硕Sentieon文献解读
Sentieon文献解读 | Population Sequencing
Sentieon文献解读 | Agrigenomics
Sentieon | Agrigenomics-泛基因组揭示小麦结构变异与栖息地及育种的关联
Sentieon文献解读 | Genetic Disease
Sentieon文献解读 | Tumor Sequencing
Sentieon文献解读 | Benchmark and Method Study
Sentieon文献解读 | Long Read Sequencing
Sentieon文献解读 | Clinical Trial
Sentieon文献解读 | Epidemiology
Sentieon文献解读 | Gene Editing
Sentieon文献解读 | Liquid Biopsy
Sentieon | TNscope 分析流程详解
-
+
首页
Sentieon-cli | DNAscope WES 流程单条命令版本详解
# 一、前言 在基因组学研究中,全外显子组测序(Whole Exome Sequencing, WES)已成为解码基因编码区域变异的常规工具,能够全面捕获人类基因组中约 2% 的外显子区域序列,从而在单核苷酸水平识别与疾病相关的功能变异,提供比全基因组测序(WGS)更经济、更深入的靶向分析手段,尤其适用于孟德尔遗传病及复杂疾病相关编码变异的发现。研究表明,WES 在多种遗传疾病中展现出重要的诊断价值——例如在神经发育障碍中其诊断率可达 25% – 40%,是临床遗传检测的一线选择之一。 然而,随着测序通量的提升与样本量的增加,基于传统 GATK 的分析流程在处理大规模 WES 数据时日益面临耗时漫长、计算资源消耗大的瓶颈,许多临床与科研团队需面对数天甚至数周的分析周期,影响了诊断时效与结果交付。 为应对这一挑战,Sentieon 开发了涵盖从比对、去重、碱基质量校正到变异检测的一体化 WES 分析加速模块,通过高度优化的算法与并行计算架构,大幅缩短全流程分析时间,为高通量WES数据提供了高效、可靠的生信分析解决方案。 * * * # 二、Sentieon-cli dnascope 流程总览 Sentieon® Genomics 软件包含一个改进的算法来执行胚系 DNA 分析的变异检测步骤。DNAscope 使用的流程类似于 DNAseq® 中描述的流程,但在比对和变异检测方面都有所不同。 DNAscope 接受模型文件以提高处理速度和准确性,除了检测 SNP 和小 indel 外,它还可以进行结构变异检测。DNAscope 的核心优势在于结合机器学习模型进行高精度变异检测,而该模型是专门为二倍体样本设计的。因此,官方明确推荐将带有机器学习模型的 DNAscope 用于人类或其他哺乳动物样本的测序数据集。 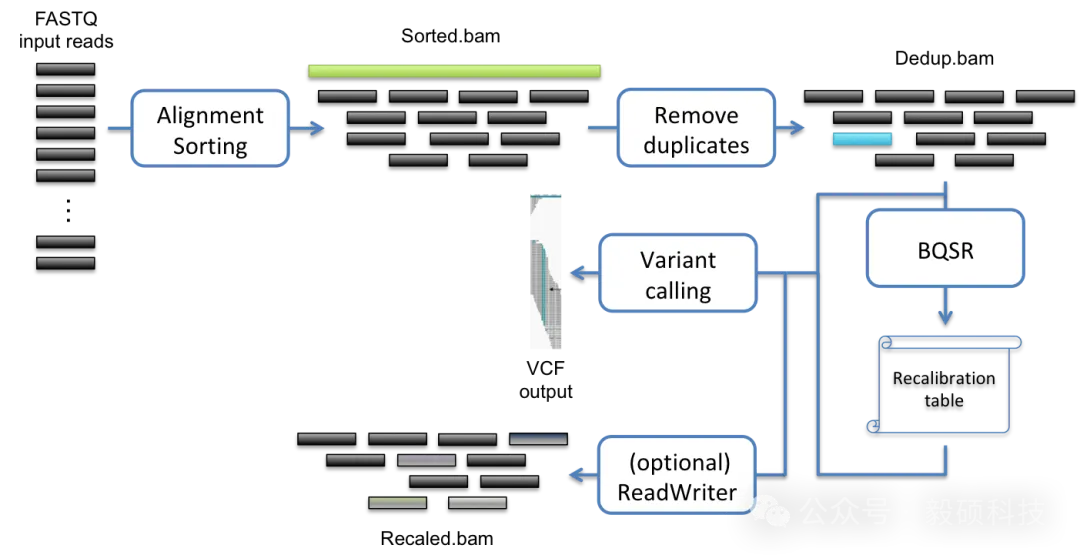 图1 推荐用于 DNA 变异检测分析的生物信息学流程 在这个生物信息学流程中,您需要以下输入文件: * FASTA 文件:包含与待分析样本对应的参考基因组核苷酸序列。 * FASTQ 文件:一个或多个包含待分析样本核苷酸序列的文件。这些文件包含来自 DNA 测序的原始读数。软件支持输入使用 GZIP 压缩的 FASTQ 文件。软件仅支持包含 Sanger 格式(Phred+33)质量分数的文件。 * 机器学习模型文件:可从 https://github.com/Sentieon/sentieon-models 获取特定测序平台机器学习模型文件。 * (可选)包含变异检测区间的 BED 文件。推荐用于全外显子组或靶向测序数据。 * (可选)您想在流程中包含的单核苷酸多态性数据库(dbSNP)数据。数据以 VCF 文件的形式使用;您可以使用 bgzip 压缩并索引的 VCF 文件。 DNAscope 的典型生物信息学分析流程包括以下步骤: 1. 将读数映射到参考基因组:此步骤将 FASTQ 文件中的读段比对并映射到 FASTA 文件中的参考基因组上。该步骤确保了数据能够被置于基因组上下文背景中(确定其路径)。 2. 计算数据指标:此步骤生成关于数据质量和流程分析质量的统计摘要。 3. 去除或标记重复:此步骤检测表明同一 DNA 分子被多次测序的读数。这些重复序列不具有信息价值,不应作为额外的证据进行计数。 4. 使用带机器学习模型的 DNAscope 进行变异检测:这一步识别您的数据相对于参考基因组显示变异的位点,并计算每个样本在该位点的基因型。 ## 1. 使用 FASTQ 文件作为输入 针对 FASTQ 格式文件,通过运行单条命令即可完成序列比对、预处理,并检测单核苷酸变异、插入缺失变异及结构变异。 ``` sentieon-cli dnascope [-h] \ -r REFERENCE \ --r1-fastq R1_FASTQ ... \ --r2-fastq R2_FASTQ ... \ --readgroups READGROUPS ... \ -m MODEL_BUNDLE \ [-d DBSNP] \ [-b INTERVAL_FILE] \ [--interval_padding 0] \ [-t NUMBER_THREADS] \ [--pcr_free] \ [-g] \ [--duplicate_marking markdup] \ [--assay WGS] \ [--consensus] \ [--dry_run] \ [--bam_format] \ SAMPLE_VCF ``` 使用 FASTQ 文件作为输入时,DNAscope 流程需要以下参数: * `-r REFERENCE`:参考序列 FASTA 文件的位置。同时需要参考序列的 fasta 索引文件 “.fai” 以及 bwa 索引文件。 * `--r1_fastq R1_FASTQ`:R1 端的输入 FASTQ 文件。可以多次指定。没有对应 R2_FASTQ 文件的 R1_FASTQ 文件将被视为单端测序数据。请注意,该流程执行单样本处理,所有 fastq 文件应来自同一个样本。 * `--r2_fastq R2_FASTQ`:R2 端的输入 FASTQ 文件。可以多次指定。 * `--readgroups READGROUPS`:每个 FASTQ 文件的读段组信息。流程将要求 --r1_fastq 参数和 --readgroups 参数具有相同数量的输入。示例参数为:--readgroups "@RG\tID:HG002-1\tSM:HG002\tLB:HG002-LB-1\tPL:ILLUMINA" * `-m MODEL_BUNDLE`:模型包文件的位置。模型包文件可在 sentieon-models 代码仓库中找到。 * `SAMPLE_VCF`:用于输出 SNV 和小插入缺失(indel)的 VCF 文件的位置。流程要求输出文件后缀为 .vcf.gz。不包含后缀的文件路径将用作其他输出文件的基础名称。 DNAscope 流程接受以下可选参数: * `-d DBSNP`:用于在 VCF 中标记已知变异的单核苷酸多态性数据库(dbSNP)的位置,文件格式为 VCF (.vcf) 或 bgzip 压缩的 VCF (.vcf.gz)。仅支持一个文件。提供此文件将用其 dbSNP 的 refSNP ID 号对变异进行注释。需要 VCF 索引文件。 * `-b INTERVAL_FILE`:用于限制变异检测的参考基因组区间,格式为 BED 文件。提供此文件将把变异检测限制在 BED 文件内的区间。如果不提供 BED 文件,软件将处理全基因组。 * `--interval_padding INTERVAL_PADDING`:在输入区间的边缘添加 INTERVAL_PADDING 个碱基的填充区域。默认值为 0。 * `-t NUMBER_THREADS`:软件将用于运行并行进程的计算线程数。此参数为可选;如果省略,流程将使用服务器所有的线程。 * `--pcr_free`:使用 --pcr_indel_model NONE 调用变异,适用于通过 PCR-free 文库制备方法构建的文库。仍会执行去重以识别光学重复。 * `-g`:除了 VCF 输出文件外,还以 gVCF 格式输出变异。工具将输出一个 bgzip 压缩的 gVCF 文件及其对应的索引文件。 * `--duplicate_marking DUP_MARKING`:重复序列标记的设置。`markdup` 将标记重复读段。`rmdup` 将删除重复读段。`none` 将跳过重复标记。默认设置为 `markdup`。 * `--assay ASSAY`:用于指标收集的检测类型设置,`WGS` 或 `WES`。默认设置为 `WGS`。 * `--consensus`:在重复标记期间生成一致性读段。 * `-h`:打印命令行帮助信息并退出。 * `--dry_run`:打印流程命令,但不实际执行。 * `--bam_format`:使用 BAM 格式而非 CRAM 格式作为输出比对文件。 ## 2. 使用未排序 BAM 或 CRAM 文件作为输入 针对未排序的 BAM 文件或 CRAM 文件,通过运行单条命令即可完成比对、预处理,并检测单核苷酸变异、插入缺失变异及结构变异。 ``` sentieon-cli dnascope [-h] \ -r REFERENCE \ -i SAMPLE_INPUT ... \ --align \ [--input_ref INPUT_REF] \ -m MODEL_BUNDLE \ [-d DBSNP] \ [-b BED] \ [--interval_padding INTERVAL_PADDING] \ [-t NUMBER_THREADS] \ [--pcr_free] \ [-g] \ [--duplicate_marking DUP_MARKING] \ [--assay ASSAY] \ [--consensus] \ [--dry_run] \ [--bam_format] \ SAMPLE_VCF ``` 当使用 uBAM 或 uCRAM 文件作为输入时,DNAscope 流程需要以下新增参数: * 必要参数: * `-i SAMPLE_INPUT`:输入样本文件,格式为 uBAM 或 uCRAM。可以通过在 `-i`参数后提供多个文件来指定一个或多个输入文件。 * `--align`:指示流程对输入的读段进行比对。 * 新增可选参数: * `--input_ref INPUT_REF`:用于解码输入文件(uCRAM)的参考序列 fasta 文件。在使用 uCRAM 输入时是必需的。此参考文件可以与 `-r`参数使用的参考文件不同。 ## 3. 使用已排序的 BAM 或 CRAM 文件 针对已经排序的 BAM 或 CRAM 文件,通过运行单条命令即可完成预处理,并检测单核苷酸变异、插入缺失变异及结构变异。 ``` sentieon-cli dnascope [-h] \ -r REFERENCE \ -i SAMPLE_INPUT ... \ -m MODEL_BUNDLE \ [-d DBSNP] \ [-b BED] \ [--interval_padding INTERVAL_PADDING] \ [-t NUMBER_THREADS] \ [--pcr_free] \ [-g] \ [--duplicate_marking DUP_MARKING] \ [--assay ASSAY] \ [--consensus] \ [--dry_run] \ [--bam_format] \ SAMPLE_VCF ``` 若不指定 `--align`和 `--collate_align`参数,流程将直接基于输入的测序序列进行变异检测。 **Sentieon-cli dnascope_wes.sh流程github地址:** https://github.com/Insvast/bioinformatics * * * # 三、流程输出 ## 1. 输出文件列表 当使用默认参数处理全基因组测序(WGS)FASTQ 数据,并设定输出文件为 `sample.vcf.gz`时,会生成以下文件: * **sample.vcf.gz**:SNV 和插入缺失(indel)的变异检测结果,覆盖由 -b 参数指定的 BED 文件所定义的基因组区域。 * **sample_deduped.cram**或 **sample_deduped.bam**:经过比对、坐标排序和重复标记的读段数据,源自输入的 FASTQ 文件。 * **sample_svs.vcf.gz**:由 DNAscope 和 SVSolver 生成的结构变异检测结果。 * **sample_metrics**:一个目录,包含所分析样本的质量控制(QC)指标。 * **sample_metrics/coverage*** :所处理样本的覆盖度指标。仅适用于 WGS 样本。 * **sample_metrics/{sample}.txt.alignment_stat.txt**:来自 AlignmentStat 算法的比对统计指标。 * **sample_metrics/{sample}.txt.base_distribution_by_cycle.txt**:来自 BaseDistributionByCycle 算法的碱基分布(按测序循环) 指标。 * **sample_metrics/{sample}.txt.dedup_metrics.txt**:来自 Dedup 算法的去重指标。 * **sample_metrics/{sample}.txt.gc_bias***:来自 GCBias 算法的 GC 偏好性指标。仅适用于 WGS 样本。 * **sample_metrics/{sample}.txt.insert_size.txt**:来自 InsertSizeMetricAlgo 算法的插入片段大小指标。 * **sample_metrics/{sample}.txt.mean_qual_by_cycle.txt**:来自 MeanQualityByCycle 算法的平均测序质量(按测序循环) 指标。 * **sample_metrics/{sample}.txt.qual_distribution.txt**:来自 QualDistribution 算法的测序质量分布指标。 * **sample_metrics/{sample}.txt.wgs.txt**:来自 WgsMetricsAlgo 算法的全基因组测序指标。仅适用于 WGS 样本。 * **sample_metrics/{sample}.txt.hybrid-selection.txt**:来自 HsMetricAlgo 算法的杂交捕获相关指标。 * **sample_metrics/multiqc_report.html**:由 MultiQC 工具汇总的综合性质量控制指标报告。 * * * # 四、实际运行测试 本次测试以人类数据为例,下载 SRP329754 项目数据并进行 dnascope 分析流程,评估其在实际中的性能表现。 ## 1. 服务器配置: * CPU 为 Intel(R) Xeon(R) Platinum 8358P CPU @ 2.60GHz 64 核心 * 内存为 512GB DDR4 * 系统为 Ubuntu 22.04.3 LTS ## 2. 软件下载安装 * https://ftp.insvast.com/user/Sentieon/release/sentieon-genomics-202503.03.tar.gz (适配 X86 架构 CPU 服务器,例如 Intel、 AMD、 曙光) * https://ftp.insvast.com/user/Sentieon/release/arm-sentieon-genomics-202503.03.tar.gz (适配 ARM 架构 CPU 服务器, 例如华为鲲鹏、 阿⾥倚天、 Ampere) * 软件下载链接用户名:insvast;密码:Ins@1234 ## 3. 参考基因组 本次分析采用 UCSC hg19 作为人类参考基因组: https://ftp.ncbi.nlm.nih.gov/genomes/all/GCF/000/001/405/GCF\_000001405.13\_GRCh37/GCF\_000001405.13\_GRCh37\_genomic.fna.gz ## 4. 分析运行 ``` dnascope_wes.sh 210 ./210 /WES-test/data/210_R1.fastq.gz /WES-test/data/210_R2.fastq.gz /WES-test/refseq/hg19.fa raw keep keep 2 /WES-test/refseq/MGI_Exome_Capture_V5_fixed.bed false dnascope_wes.sh 69 ./69 /WES-test/data/69_R1.fastq.gz /WES-test/data/69_R2.fastq.gz /WES-test/refseq/hg19.fa raw keep keep 2 /WES-test/refseq/MGI_Exome_Capture_V5_fixed.bed false ``` * * * # 五、分析结果展示 ## 1. 输出文件 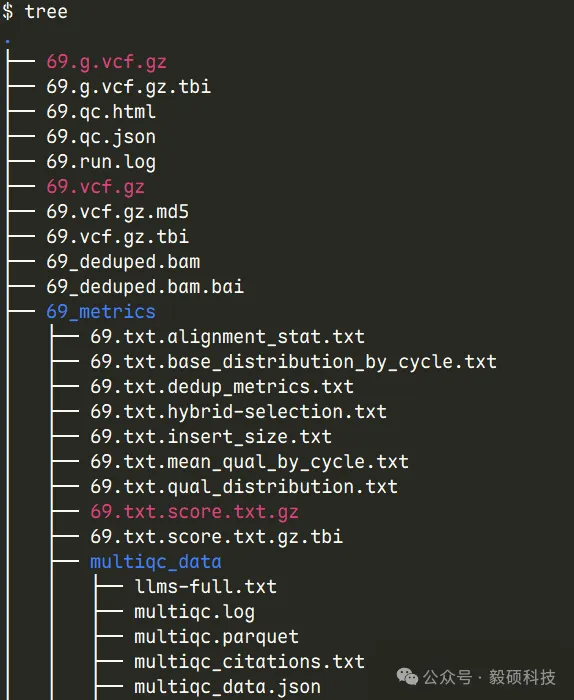 ## 2. qc结果展示 | |S210|S69| |--|--|--| |[Total] Raw Reads (All reads)|174018654|175532558| |[Total] QC Fail reads|0|0| |[Total] Raw Data(Mb)|29513.66|29343.35| |[Total] Paired Reads|139031504|147210368| |[Total] Mapped Reads|173940344|175484524| |[Total] Fraction of Mapped Reads|99.96%|99.97%| |[Total] Mapped Data(Mb)|29501.94|29336.25| |[Total] Fraction of Mapped Data(Mb)|99.96%|99.98%| |[Total] Properly paired|133742970|144067426| |[Total] Fraction of Properly paired|76.86%|82.07%| |[Total] Read and mate paired|138931672|147150094| |[Total] Fraction of Read and mate paired|79.84%|83.83%| |[Total] Singletons|21522|12240| |[Total] Read and mate map to diff chr|4557730|2596934| |[Total] Read1|69515752|73605184| |[Total] Read2|69515752|73605184| |[Total] Read1(rmdup)|15761633|18869429| |[Total] Read2(rmdup)|15761525|18869118| |[Total] forward strand reads|89536187|88441568| |[Total] backward strand reads|84404157|87042956| |[Total] PCR duplicate reads|107430036|109423787| |[Total] Fraction of PCR duplicate reads|61.76%|62.36%| |[Total] Map quality cutoff value|20|20| |[Total] MapQuality above cutoff reads|169946341|171121552| |[Total] Fraction of MapQ reads in all reads|97.66%|97.49%| |[Total] Fraction of MapQ reads in mapped reads|97.70%|97.51%| |[Insert size] Average|288.32|300.24| |[Insert size] Median|289|303| |[Target] Target Reads|136622510|137462492| |[Target] Fraction of Target Reads in all reads|78.51%|78.31%| |[Target] Fraction of Target Reads in mapped reads|78.55%|78.33%| |[Target] Target Data(Mb)|20336.51|20046.92| |[Target] Target Data Rmdup(Mb)|9050.95|8545.6| |[Target] Fraction of Target Data in all data|68.91%|68.32%| |[Target] Fraction of Target Data in mapped data|68.93%|68.33%| |[Target] Len of region|69059980|69059980| |[Target] Average depth |294.48 |290.28| |[Target] Average depth(rmdup)|131.06|123.74| |[Target] Coverage (>0.2*(Average depth)x)|93.56%|91.98%| |[Target] Coverage (>0.5*(Average depth)x)|68.28%|67.77%| |[Target] Coverage (>0x)|99.38%|99.25%| |[Target] Coverage (>=4x)|99.10%|98.83%| |[Target] Coverage (>=10x)|98.66%|97.99%| |[Target] Coverage (>=30x)|97.20%|95.98%| |[Target] Coverage (>=100x)|83.00%|81.46% | multiqc_report.html 界面展示: 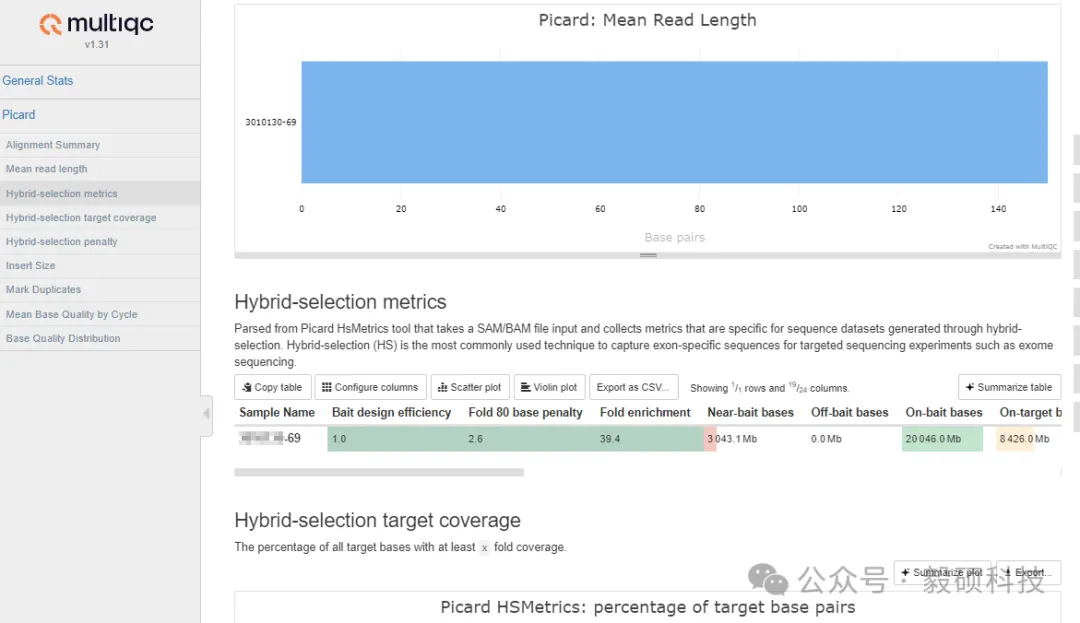 本次测试的 2 个人类样本数据产出稳定(单样本~ 8GB),有效率 >99.86% 且Q30 高达 93.7% 以上,测序质量与准确度极佳。GC含量(~ 43.1%)与插入片段分布表现出高度的样本间一致性,唯一比对率稳定在 99.9% 左右,证明文库质量优异,完全符合差异表达或变异检测等高标准下游分析要求。 ## 3. 用时统计 ||S210|S69| |--|--|--| |fastq文件质控时间(min)|3.7|3.65| |DNAscope变异检测时间(min)|27.72|26.3| |总时间(min)|31.43|29.95| 如果不需要sv结果可以在分析参数中指定 `--skip-svs`,能进一步压缩分析时间: 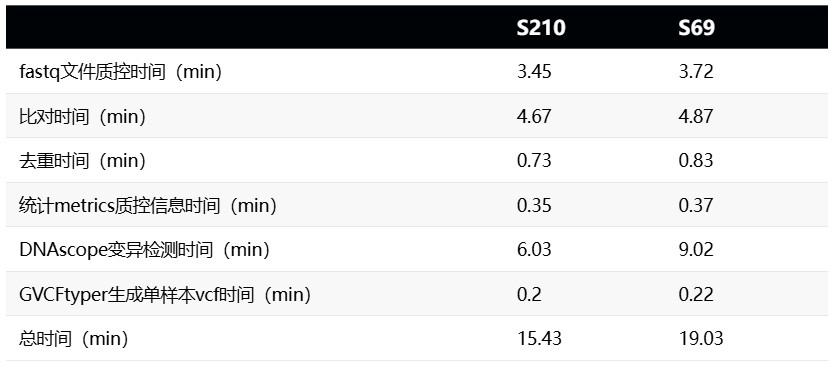 在 64 核测试服务器上 16G 数据量的人类 WES 数据(294X)平均分析仅耗时 15.43 min,极大缩短了分析时间,加快科研成果转化。Sentieon 在不断的优化算法的运行效率,为科研工作者提供更快速、更经济的基因检测方案。 若您刚好有需要检测的数据,不妨来申请试用 Sentieon 吧! **Sentieon-cli dnascope 官方文档:** https://support.sentieon.com/docs/sentieon\_cli/#dnascope
chsnp
2026年4月16日 15:55
转发
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
Word文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码
有效期