HPC
DCV 应用教程
DCV | Nice DCV 安装手册
DCV | RLM 提取 HOSTID
EF Portal and DCV HA Solution
Enginframe 应用教程
Enginframe | 技术参数说明
毅硕HPC教程
毅硕HPC | HPC环境下的LDAP配置
毅硕HPC | Rocky Linux 9 SLURM软件编译安装
毅硕HPC | RHEL 8 上的NVIDIA驱动安装
毅硕HPC | 配置SLURM作业队列优先级
毅硕HPC | Pritunl + ECS + Frp 搭建远程办公VPN
毅硕HPC | 在HPC集群上优雅地使用 Conda
毅硕HPC | 一文详解HPC环境中的MPI并行计算
毅硕HPC | NVIDIA DGX Spark 万字硬核评测:将AI超级工厂带上桌面
毅硕HPC | Lustre文件系统在HPC集群中的部署实战
毅硕HPC | InfiniBand网络在HPC集群中的核心应用
毅硕HPC | OpenPBS构建高效稳定的HPC作业调度环境
毅硕HPC | HPC集群LSF调度系统部署指南
毅硕HPC | 轻量高效的XFCE桌面环境
毅硕HPC | Ubuntu 24 SLURM 编译安装
-
+
首页
毅硕HPC | HPC集群LSF调度系统部署指南
在高性能计算(HPC)的世界里,如果说昂贵的GPU和计算节点是引擎,那么集群调度系统就是那台精准的离合器。许多企业在投入千万级硬件成本后,依然面临“任务排队久、资源分配不均、节点空转”的尴尬局面。 LSF(Load Sharing Facility)作为业界公认的顶级调度器,其价值不仅在于“分配任务”,更在于如何通过精细化的策略,将杂乱无章的计算需求转化为高效流转的数字化生产线。本文将带你深入实施一线,手把手拆解LSF的安装部署与实战配置。 * * * # 一、 核心架构概览 我们可以将 LSF(Load Sharing Facility)的逻辑架构拆解为核心组件、节点角色、数据流向三个维度来理解。 LSF 的本质是一个多层级的分布式管理系统,通过各个守护进程(Daemon)的协同,实现任务从提交到执行的全生命周期管理。 ## 1\. 集群架构简图 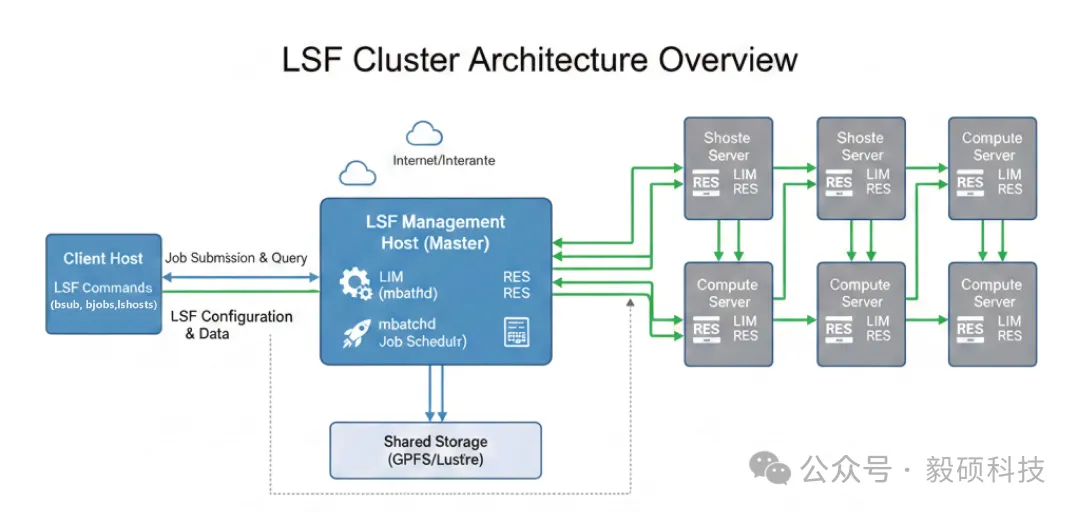 ## 2\. 三大守护进程 逻辑架构的稳定运行依赖于这三个关键进程,它们在图中展示的 Master 和 Compute 节点上各司其职: * LIM (Load Information Manager):负载收集器 * 作用:它是整个集群的“眼睛”。运行在每个节点上,实时收集 CPU 利用率、内存剩余、磁盘空间以及 GPU 状态等信息。 * 逻辑:所有节点的 LIM 将数据汇聚给 Master 节点上的 Master LIM,由其汇总成一张全集群的“资源动态地图”。 * RES (Remote Execution Server):远程执行器 * 作用:它是任务执行的“手”。负责接收运行请求,并创建一个安全、透明的远程运行环境。 * 逻辑:当任务被分配到某个计算节点时,该节点的 RES 负责启动并监控该进程。 * sbatchd (Slave Batch Daemon):批处理守护进程 * 作用:它是任务的“监工”。主要负责与 Master 节点的调度器通信,接收任务指令,管理任务状态,并向 Master 回传任务执行结果。 ## 3\. 节点角色定位 从架构图中可以清晰看到三类角色的分工: * LSF Management Host (Master Node): * 运行 mbatchd(批处理主进程)和 mbschd(调度插件)。 * 它是“大脑”,负责接收来自 Client 的 `bsub` 指令,并根据队列规则(Priority, Fairshare)决定任务该去哪。 * Compute Server (Execution Node): * 纯粹的任务承载者。它们运行 LIM、RES 和 sbatchd,等待 Master 派发活计。 * Client Host (Submission Node): * 用户交互层。通常只安装 LSF 的命令工具,用户在这里执行 `bsub`、`bjobs` 或 `bqueues`。 ## 4\. 逻辑数据流向 * 提交阶段: 用户在 Client Host 发起 `bsub`,请求通过网络发送给 Master 上的 `mbatchd`。 * 调度阶段: `mbatchd` 询问 `mbschd`(调度器):“现在哪个节点最闲且符合用户要求?”调度器结合 `Master LIM` 汇总的资源地图做出决策。 * 分发阶段: Master 将任务指令发送给目标 Compute Server 的 `sbatchd`。 * 执行阶段: `sbatchd` 调用 `RES` 启动任务,任务运行期间的 I/O 直接与 Shared Storage (GPFS/Lustre) 交互,确保数据一致性。 * 反馈阶段: 任务结束后,`sbatchd` 通知 Master 任务完成,Master 更新状态并将日志(stdout/stderr)写回用户指定位置。 * * * # 二、 实施过程:详细配置步骤 ## 1\. 环境预检查 * 无密码互信: Root 及普通用户的 SSH 免密登录。 * 共享文件系统: LSF 的配置目录和工作目录必须放在共享存储(如 GPFS, Lustre 或 NFS)上。 * 用户与权限: 所有节点必须有统一的账号体系(LDAP/NIS)。 * 管理账号(通常为 `lsfadmin`)必须在所有节点拥有相同的 UID/GID。 * 内核参数优化: 修改 `/etc/security/limits.conf`,将 `nofile`(打开文件数)和 `nproc`(进程数)调至 65535 以上,防止高并发任务导致系统崩溃。 由于正式版(LSF Standard)需要license,这里我们采用社区版(LSF Suite Community Edition)来安装测试:  注册或登录IBMid:  访问 https://epwt-www.mybluemix.net/software/support/trial/cst/programwebsite.wss?siteId=680&h=null&p=null 下载 lsfsce10.2.0.15-x86\_64.tar.Z :  在共享目录解压:  进入 lsf 目录继续解压 lsf10.1_lsfinstall_linux_x86_64.tar.Z:  ## 2\. 安装及配置 * install.config 配置文件: 配置 `LSF_TOP`, `LSF_ADMINS`, `LSF_CLUSTER_NAME` 等核心参数。 ``` LSF_TOP="/opt/lsf" LSF_ADMINS="lsfadmin" LSF_CLUSTER_NAME="lsf-dev" LSF_MASTER_LIST="rhel-lsf-master" LSF_TARDIR="/lsf-package/lsfsce10.2.0.15-x86_64/lsf" CONFIGURATION_TEMPLATE="HIGH_THROUGHPUT" LSF_ADD_SERVERS="rhel-lsf-master" LSF_ADD_CLIENTS="rhel-lsf-worker" # 配置项说明 LSF_TOP : 设置安装路径。 LSF_ADMINS : 设置管理员账号,建议创建一个公用的管理员账号 lsfadmin。 LSF_CLUSTER_NAME : 集群名称。 LSF_MASTER_LIST :master 机器列表,如果有多台机器,建议至少设置两台 master,作为冗余备份。 LSF_TARDIR : 安装文件解压缩路径。 CONFIGURATION_TEMPLATE :配置模式,如果是 IC 应用场景,建议设置为 HIGH_THROUGHPUT 高性能模式。 LSF_ADD_SERVERS :添加计算机节点机器,也可以安装后配置。 LSF_ADD_CLIENTS :添加客户机(投递机)节点,也可以安装后配置。 ``` * 执行安装脚本: * 解压与权限: 以 root 权限运行,确保 `lsfinstall` 脚本具有执行权限。 * 执行安装:`bash ./lsfinstall -f install.config`  到安装目录的 conf 路径下,将 lsf.conf 文件中 LSF_RSH=ssh 取消注释: ``` # As a best practise, use scp and ssh here for security # Registering ssh host fingerprints is required before using these # Otherwise, "-o StrictHostKeyChecking=no" can be used to skip this step # LSF_REMOTE_COPY_CMD=scp -B LSF_RSH=ssh LSF_SERVER_HOSTS="rhel-lsf-master" LSF_MASTER_LIST="rhel-lsf-master" LSF_EGO_DAEMON_CONTROL=N ``` 拷贝文件 cshrc.lsf 和 profile.lsf 到 /etc/profile.d/ 可以开机自动加载 lsf 环境 ``` # cp cshrc.lsf profile.lsf /etc/profile.d/ ``` 手工载入环境。如果是 csh/tcsh 则 source cshrc.lsf,否则 source profile.lsf ``` [root@rhel-lsf-master conf]# echo $SHELL /bin/bash [root@rhel-lsf-master conf]# source profile.lsf ``` * 主机脚本处理: 安装完成后,LSF 会在 `LSF_TOP/10.1/install/`下生成`hostsetup`脚本。 * 在所有节点 root 账号执行:`./hostsetup --top="/opt/lsf" --boot="y"`  * 此步骤会自动配置内核设备文件并设置开机自启服务。 * 使用 root 登录 master 节点,执行以启动 lsf 集群。 ``` lsfstartup ``` * 如果遇到: ``` lsadmin: error while loading shared libraries: libnsl.so.1: cannot open shared object file: No such file or directory Error(s) found in previous operation, continue ? [y/n]n ``` * 安装 libnsl 再启动: ``` yum install libnsl.x86_64 ``` * 核心配置文件: LSF 的配置精髓在于 `conf/lsbatch/<cluster_name>/configdir/` 下的几个文件: `lsb.hosts`:资源定义 在这里定义节点的“组”属性和资源上限。 * 技巧: 将同机型的节点归为一类(HostGroup),便于后续按机型投递任务。 * 配置项: `MXJ`(最大槽位数),建议设置为物理核心数的 1 到 1.2 倍。 ``` # 文件路径参考: $LSF_CONFDIR/lsbatch/<cluster_name>/configdir/lsb.hosts # ---------------------------------------------------------------- # 1. Host Section: 定义单台主机的物理限制 # ---------------------------------------------------------------- Begin Host HOST_NAME MXJ r1m pg ls tmp DISPATCH_WINDOW AFFINITY # MXJ: 最大作业数(Slots)。通常设为物理CPU核心数的 1 到 1.2 倍 # r1m: 1分钟平均负载阈值,超过则不再派发任务 # AFFINITY: 是否开启 CPU 亲和力(Y/N) default ! () () () () () (Y) rhel-lsf-master 0 () () () () () (N) # 管理节点不跑任务 rhel-lsf-worker 16 3.5 () () 1024 () (Y) # 16核,负载超3.5即停 End Host # ---------------------------------------------------------------- # 2. HostGroup Section: 将主机逻辑归类 # ---------------------------------------------------------------- # 在队列配置里可以直接引用组名,方便后续横向扩展节点。 Begin HostGroup GROUP_NAME GROUP_MEMBER # 包含所有通用计算节点 all_nodes (rhel-lsf-worker01 rhel-lsf-worker02) # 专门的 GPU 节点组 gpu_nodes (gpu-node01 gpu-node02) # 针对特定部门的预留节点 dept_eda (eda-node01 eda-node02) End HostGroup ``` `lsb.queues`:调度逻辑的核心 你需要根据业务需求配置不同队列: * 优先级(PRIORITY): 核心业务队列优先级设为 30,普通队列设为 20。 * 资源限制示例: ``` Begin Queue QUEUE_NAME = high_priority PRIORITY = 50 U_LIMIT = 2 # 每个用户最多同时运行2个任务 HOSTS = group_fast_nodes # 只在高性能节点运行 End Queue ``` ## 3\. 初始化与启动 * 设置环境变量:`source profile.lsf`。 * 服务启动顺序:从 Master 开始启动 `lsfadmin lim`, `res`, `sbatchd`。 ## 4\. 配置验证 服务启动与检查 ``` lsid # 检查集群基本信息 lsload # 检查节点负载是否正常上报 [root@rhel-lsf-master lsf10.1_lsfinstall]# lsid IBM Spectrum LSF Community Edition 10.1.0.15, May 13 2025 Copyright IBM Corp. 1992, 2016. All rights reserved. US Government Users Restricted Rights - Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. My cluster name is lsf-dev My master name is rhel-lsf-master [root@rhel-lsf-master lsf10.1_lsfinstall]# lsload HOST_NAME status r15s r1m r15m ut pg ls it tmp swp mem rhel-lsf-master ok 0.1 0.0 0.0 5% 0.0 1 1 23G 3.9G 6.5G ``` 提交流程测试 * 简单测试:`bsub -n 2 "sleep 300"` ``` [lsfadmin@rhel-lsf-master ~]$ bsub -n 2 "sleep 300" Job <101> is submitted to default queue <normal>. [lsfadmin@rhel-lsf-master ~]$ lsload HOST_NAME status r15s r1m r15m ut pg ls it tmp swp mem rhel-lsf-master ok 0.0 0.0 0.1 3% 0.0 1 0 23G 3.9G 6.4G [lsfadmin@rhel-lsf-master ~]$ bqueues normal QUEUE_NAME PRIO STATUS MAX JL/U JL/P JL/H NJOBS PEND RUN SUSP normal 30 Open:Active - - - - 2 0 2 0 ``` * 交互测试: `bsub -Ip /bin/bash` * 资源申请测试:`bsub -n 4 -R "span[hosts=1] rusage[mem=1024]" my_job` * * * # 三、 实战配置:让集群调度更智能 ## 1\. 动态资源限制: 在多用户环境下,常有用户因程序Bug(如死循环、内存泄漏)拖垮整个节点。通过 `lsb.resources` 定义限制,可以实现物理隔离。 * 配置目标: 限制单个用户在 `normal` 队列中最多只能占用 100 个核心和 500GB 内存。 * `lsb.resources` ``` Begin Limit NAME = user_limit USERS = all # 针对所有用户 QUEUES = normal # 仅限 normal 队列 SLOTS = 100 # 最大槽位限制 MEM = 512000 # 最大内存限制 (MB) End Limit ``` ## 2\. 公平共享策略 (Fairshare): 这是企业级HPC的核心需求。如果不配置 Fairshare,先提交 10000 个任务的用户会堵死后来的所有任务。 * 逻辑: 按照权重分配算力。如果 A 组权重为 10,B 组权重为 5,当资源紧张时,A 组获得的算力将是 B 组的两倍。 * `lsb.queues` ``` Begin Queue QUEUE_NAME = compute ... # 开启公平共享:给研发一部 100 份权重,研发二部 50 份权重 FAIRSHARE = USER_SHARES[[GroupA, 100] [GroupB, 50]] End Queue ``` ## 3\. 抢占机制 (Preemption): 在 EDA 仿真或生物制药筛选中,常有“特急”任务。通过抢占配置,可以让高优先级任务强制“挂起”低优先级任务,任务完成后自动恢复。 * 配置技巧: 1. 在 `high` 队列设置 `PREEMPTIVE = all`。 ``` Begin Queue QUEUE_NAME = critical PRIORITY = 100 # 优先级要设高 # 允许抢占哪些队列。'all' 表示所有队列。 # 也可以写具体的队列名,如 PREEMPTIVE = normal low PREEMPTIVE = all ... End Queue ``` 2. 在 `low`队列设置`PREEMPTABLE = all`。 ``` Begin Queue QUEUE_NAME = low_priority PRIORITY = 10 # 允许被哪些队列抢占。'all' 表示可以被任何抢占队列抢。 PREEMPTABLE = all ... End Queue ``` * 效果: 当 `high` 队列任务进入时,若资源满载,LSF 会自动将 `low` 队列任务状态转为`SSUSP`,释放资源。 ## 4\. LSF 任务状态流转详解 * 提交阶段 (Submission) - 状态:`PEND` * 动作: 用户在客户端执行`bsub`。 * 逻辑流:`bsub`命令将任务请求发送给 Master 节点的 mbatchd。 * mbatchd 验证用户权限、队列定义和资源要求(Resource Requirements)。 * 如果验证通过,任务进入 `PEND`(挂起)状态,记录在 `lsb.events` 日志中。 * 调度阶段 (Scheduling) - 状态:`PEND` * 动作: mbschd 插件每隔一段时间(Scheduling Cycle)扫描一次 PEND 桶。 * 逻辑流:调度器检查 Master LIM 汇总的各节点实时负载。 * 根据优先级、Fairshare 权重、预留资源(Reservation)等算法,为任务选定最合适的“宿主”节点。 * 一旦选定,任务状态准备从 `PEND` 转向 `RUN`。 * 执行阶段 (Execution) - 状态:`RUN` * 动作: mbatchd 指令下发至计算节点的 sbatchd。 * 逻辑流:计算节点的 sbatchd 派生(Fork)一个子进程(称为 res 或 child sbatchd)。 * 该进程设置执行环境(环境变量、家目录、工作目录)。 * 重点: 任务正式启动。此时执行 `bjobs` 会看到任务处于 `RUN` 状态。 * 实时监控: sbatchd 持续监控任务的资源消耗(CPU、MEM),并定期汇报给 Master。 * 异常干预阶段(可选) - 状态:`SUSP` / `USUSP` / `SSUSP` * 动作: 任务可能因为资源竞争或手动干预被暂停。 * 逻辑流:`USUSP`:用户手动执行`bstop`暂停任务。 * `SSUSP`:系统因为节点负载过高(如内存即将耗尽)自动挂起任务,优先保障核心进程。 * 结束阶段 (Termination) - 状态:`DONE` 或 `EXIT` * 动作: 任务进程结束,sbatchd 收集“临终信息”。 * 逻辑流:DONE: 任务正常退出,退出码为 $0$。 * EXIT: 任务异常结束(如因 OOM 被系统杀掉、代码报错等),退出码非 0。 * 清理: LSF 清理该任务产生的临时文件(如 `/tmp` 目录下的缓存),回收 CPU Slots 和 GPU 资源。 * 回传: Master 节点收集 `stdout` 和 `stderr`,根据用户设置通过邮件发送或写入指定文件。 ## 5\. 避坑指南与常见状态排查 * DNS 逆向解析: LSF 对主机名非常敏感。如果 DNS 不稳定,必须在所有节点的`/etc/hosts` 中硬写主机名。 * 防火墙端口: 确保 `LIM_PORT` (703), `RES_PORT` (705), `SBD_PORT` (707) 双向开启。 * 时间同步: 所有节点的时间偏差必须小于 1秒,否则 `lsfadmin` 通讯会因安全校验失败。 |状态|常见原因|排查命令 / 技巧| |--|--|--| |持久 PEND|资源不足(内存/显卡)、队列限制、优先级低|bjobs -p (LSF 会直接告诉你原因)| |UNKWN|计算节点与 Master 失去心跳(网络或 sbatchd 崩溃)|在节点执行 lsf_daemons status| |ZOMBI|任务已被杀死但进程未完全清理(僵尸进程)|检查节点是否有残留的进程树| |EXIT (137)|通常是由于内存溢出(OOM)被 LSF 强制杀死|bhist -l检查 Max Memory 占用| * * * # 四、LSF 的 GPU 自动化调度 在 LSF 10.1 及更高版本中,LSF 引入了 GPU 自动发现 (GPU Autodetection) 功能。这意味着你不再需要手动统计每台机器有多少显卡,LSF 会通过`nvidia-smi`自动同步。 ## 1. 开启 LSF 的 GPU 监控 首先,在 `lsf.conf` 中启用 GPU 资源统计功能: Bash ``` # 修改 lsf.conf LSB_GPU_NEW_SYNTAX=Y # 启用新的 GPU 语法(推荐,功能更强) LSF_GPU_AUTOCONFIG=Y # 开启自动检测 ``` ## 2\. 配置资源定义 (`lsf.shared` ) 确保 LSF 识别 GPU 资源类型。如果配置文件中没有,需要手动补充: ``` Begin Resource RESOURCENAME TYPE INTERVAL INCREMENT DESCRIPTION gpu Numeric 30 Y (GPU resource) ngpus_physical Numeric 30 Y (Number of physical GPUs) gpu_driver String () () (GPU driver version) End Resource ``` ## 3\. 定义集群资源 (`lsb.resources` ) 为了防止 GPU 被过度使用或未授权占用,我们需要定义 GPU 资源池。通过 `GPU_USAGE` 参数,LSF 可以管理显存(GPU Memory)和独占模式(Exclusive Mode)。 * `mode` (运行模式) * 定义任务对 GPU 核心的占用方式: * `shared` (默认): 允许多个任务共享同一个 GPU。适用于显存占用小、计算强度不高的任务。 * `exclusive_process`: 对应 NVIDIA 的独占模式。一个 GPU 同时只能被一个进程(及其子进程)占用。这是 HPC 生产环境(如 AI 训练)最常用的设置,防止不同用户的任务互相抢夺 CUDA Core。 * `j_exclusive` (任务独占) * `yes` / `no`: 定义该任务是否要“包场”。 * 如果设为 `yes`,一旦该任务申请了某张显卡,即使该任务只用了 1GB 显存,其他任务也无法再进入这张显卡。这提供了最严苛的硬件隔离。 * `mps` (Multi-Process Service) * `yes` / `no` / `share`: 是否开启 NVIDIA MPS。 * 作用: MPS 能让多个进程并行地在同一个 GPU 上执行,通过硬件漏斗合并请求,能显著提高小规模任务的 GPU 利用率。 * `gmem` (显存量) * 作用: 限制任务可用的物理显存。 * 配合: 当用户提交 `bsub -gpu "num=1:gmem=8G"` 时,LSF 会通过内部算法挑选出剩余显存大于 8GB 的卡。 * `gtile` (卡间拓扑) * 示例: `gtile=2` * 作用: 规定任务在多卡环境下的分布。例如,申请 4 块卡,`gtile=2` 表示在每个物理 Socket(或每个主板)上均匀分配 2 块卡,以优化 NVLink 通信效率。 **场景 A:严苛的 AI 训练队列(独占且独享)** 要求任务必须独占显卡,且一张卡不准进第二个任务。 ``` Begin Queue QUEUE_NAME = AI_Train # 强制所有进入该队列的任务都遵循此 GPU 策略 GPU_USAGE = /mode=exclusive_process/j_exclusive=yes End Queue ``` **场景 B:灵活的开发调试队列(共享并开启 MPS)** 允许用户共享显卡,提高吞吐量。 ``` Begin Queue QUEUE_NAME = GPU_Debug # 允许多个用户共享 GPU,并开启 MPS 优化 GPU_USAGE = /mode=shared/mps=yes End Queue ``` ## 4\. 作业投递中的 GPU 参数 `-gpu` LSF 的 `-gpu`选项可以实现非常复杂的调度逻辑: * 申请指定数量的 GPU:`bsub -gpu "num=2" my_job` (申请 2 块显卡) * 指定 GPU 拓扑(NVLink): 在多卡训练中,显卡间的通信带宽至关重要。 `bsub -gpu "num=4:mode=exclusive_process:j_exclusive=yes" -R "same[boardid]" my_job`这里的 `same[boardid] `确保所有分配的 GPU 都在同一个物理板卡或拓扑范围内,以利用 NVLink 的最大带宽。 * 显存独占与模式限制:`bsub -gpu "num=1:mode=shared:mps=yes" my_job`开启 NVIDIA MPS (Multi-Process Service),允许显存被多个子进程共享,提高低负载任务的利用率。 * * * # 五、结语 HPC 实施从来不是简单的软件包安装,而是一场关于“资源与效率”的艺术平衡。一套配置精良的 LSF 系统,能让科研人员告别繁琐的命令行等待: * 资产透明化: 客户不再需要记录哪台机器有 A100,哪台有 H100,LSF 自动绘图展示。 * 避免算力冲突: 通过 `exclusive`模式,防止两个 AI 训练任务抢夺同一块显卡的显存,导致程序 OOM(内存溢出)。 * 保障业务连续性: LSF 的高可用(HA)配置,确保 Master 宕机时计算任务不中断。 * 支持异构计算: 完美适配 CPU+GPU 混合调度,自动识别 NVIDIA 显卡拓扑。
chsnp
2026年1月28日 15:24
转发
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
Word文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码
有效期