HPC
DCV 应用教程
DCV | Nice DCV 安装手册
DCV | RLM 提取 HOSTID
EF Portal and DCV HA Solution
Enginframe 应用教程
Enginframe | 技术参数说明
毅硕HPC教程
毅硕HPC | HPC环境下的LDAP配置
毅硕HPC | Rocky Linux 9 SLURM软件编译安装
毅硕HPC | RHEL 8 上的NVIDIA驱动安装
毅硕HPC | 配置SLURM作业队列优先级
毅硕HPC | Pritunl + ECS + Frp 搭建远程办公VPN
毅硕HPC | 在HPC集群上优雅地使用 Conda
毅硕HPC | 一文详解HPC环境中的MPI并行计算
毅硕HPC | NVIDIA DGX Spark 万字硬核评测:将AI超级工厂带上桌面
毅硕HPC | Lustre文件系统在HPC集群中的部署实战
毅硕HPC | InfiniBand网络在HPC集群中的核心应用
毅硕HPC | OpenPBS构建高效稳定的HPC作业调度环境
毅硕HPC | HPC集群LSF调度系统部署指南
毅硕HPC | 轻量高效的XFCE桌面环境
毅硕HPC | Ubuntu 24 SLURM 编译安装
-
+
首页
毅硕HPC | NVIDIA DGX Spark 万字硬核评测:将AI超级工厂带上桌面
# 一、开启本地AI开发的新纪元 在生成式AI飞速发展的今天,每一位开发者都渴望拥有无拘无束的算力。不再受制于云端排队、网络延迟或数据隐私的顾虑——NVIDIA DGX Spark横空出世让这一切有了可能。 它不仅仅是一台计算机,它是浓缩在精致桌面机箱中的AI数据中心。作为全球首款基于NVIDIA Grace Blackwell架构的个人AI超级计算机,DGX Spark将工业级的AI性能带入您的私人工作空间,让您从原型设计到大规模部署,实现真正的无缝衔接。 * * * # 二、NVIDIA DGX Spark:小巧机身,PetaFLOP级算力 NVIDIA DGX Spark的核心优势在于其先进的架构和强大的计算能力,它为本地AI开发提供了工业级的AI体验。NVIDIA DGX Spark的心脏,是革命性的NVIDIA GB10 Grace Blackwell超级芯片。在紧凑的桌面端外形中,集成了前所未有的计算密度。 ## 1. 令人惊叹的计算性能 * 1 PetaFLOP AI算力:DGX Spark可提供高达每秒1千万亿次的AI计算性能。这意味着您在办公桌上就拥有了过去需要服务器机架才能实现的算力。 * 第五代Tensor Core:搭载基于Blackwell架构的GPU,专为处理最复杂的AI工作负载而生。 * 高性能混合计算:内置20核Grace Arm CPU(10个Cortex-X925+10个Cortex-A725),强效助力数据预处理和编排,加速从数据清洗到模型调整的全流程。 ## 2. 突破瓶颈的统一内存架构 传统架构中,数据在CPU和GPU内存之间的搬运是最大的性能杀手。DGX Spark彻底改变了这一点: * 128GB统一寻址内存 (LPDDR5x):128GB的统一寻址系统内存,支持对FP4数据格式。 * NVLink-C2C互联技术:提供CPU与GPU间的一致性内存模型,带宽是第五代PCIe的5倍。 * * * # 三、 NVIDIA DGX Spark:专为大模型 (LLM) 而生 DGX Spark专为解决生成式AI模型规模和复杂性日益增长带来的挑战而设计,特别针对本地进行大模型的原型设计、微调和推理。 ## 1. 单机驾驭200B参数模型 凭借128GB的统一寻址系统内存和对FP4数据格式的支持,单个NVIDIA DGX Spark系统可以支持对多达200B参数的模型进行试验、微调或推理。这使AI开发人员能够在桌面端对新一代AI推理模型进行原型设计、微调和推理。您可以在本地安全地对新一代开源模型进行微调 (Fine-tuning)、量化验证或高吞吐量推理,无需将敏感数据上传至云端。  ## 2. 双机互联,挑战405B参数极限 DGX Spark内置了NVIDIA ConnectX™智能网卡。通过NVIDIA ConnectX互联技术,可以连接两台NVIDIA DGX Spark AI超级计算机。这种扩展能力支持对多达405B参数的模型进行推理,例如Llama 3.1 405B等更大的模型。  通过高速互联技术连接两台DGX Spark,构建您的桌面微型AI集群。这种组合可支持高达4050亿 (405B) 参数的超大模型推理(例如 Llama 3.1 405B)。这是目前市场上罕见的、能在办公桌面上运行顶级大模型的解决方案。 ## 3. 部署与迁移 NVIDIA DGX Spark支持本地开发,随时随地进行大规模部署。用户可以将其模型从桌面端无缝迁移到DGX Cloud或任何加速云或数据中心基础设施,几乎无需更改代码。这使得原型设计、微调和迭代过程比以往都更容易。 * 原厂软件生态:预装NVIDIA DGX OS和Ubuntu Linux,以及最新的NVIDIA AI软件堆栈。 * 开箱即用:开发者可直接访问 NVIDIA NIM™和NVIDIA Blueprint,并流畅使用PyTorch、Jupyter和Ollama等主流工具。 * 从桌面到数据中心:您在DGX Spark上开发的模型,无需修改代码即可无缝迁移至DGX Cloud或企业级数据中心。它是您低成本、高效率的实验场。 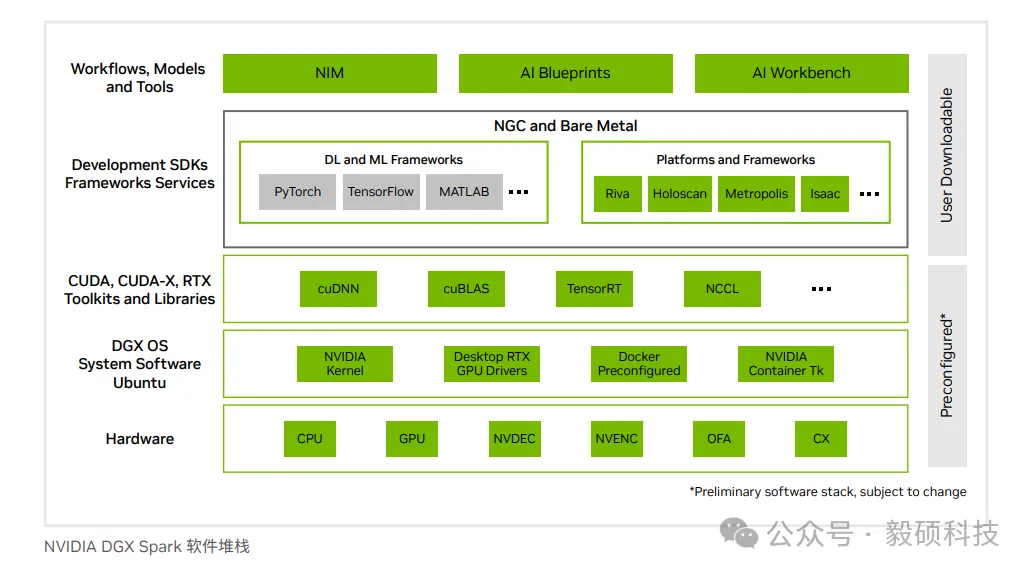 * * * # 四、 详细技术规格摘要 DGX Spark在小巧的桌面端外形中提供了出色的性能和强大的功能,旨在帮助开发者、研究人员、数据科学家和学生突破生成式AI的边界。 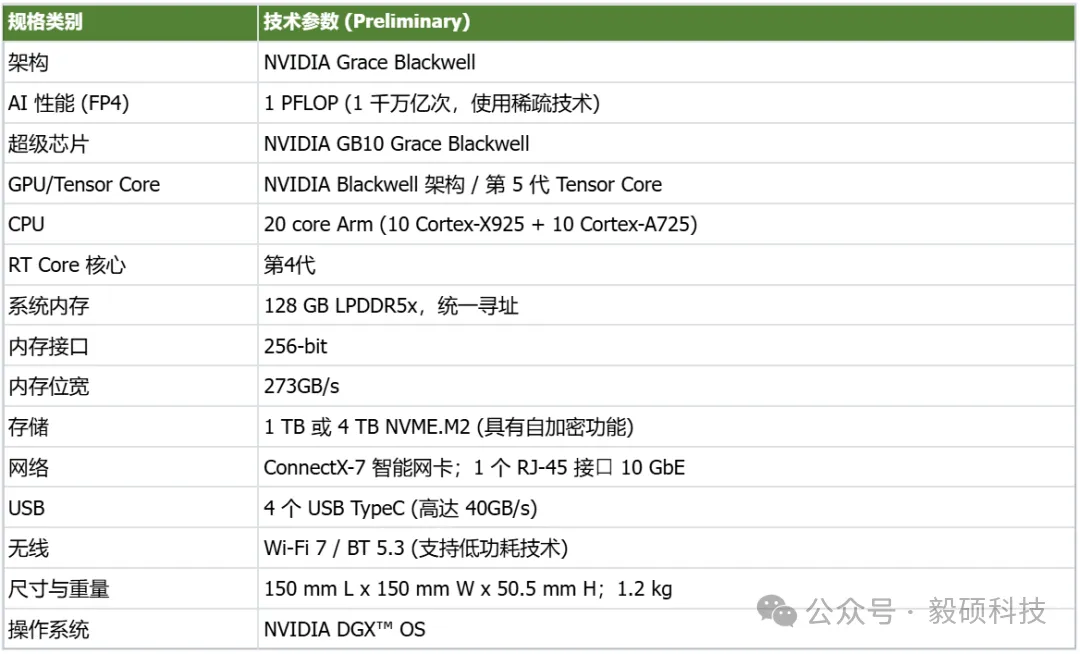   * * * # 五、大模型测试 ## 1\. 主流模型测试 本次测试目标明确:验证DGX Spark能否加载并运行对单卡而言“不可能”的模型。测试结果完美印证了其核心定位,Qwen、DeepSeek等主流大模型均能在DGX Spark上成功加载并稳定运行,充分展现了其强大的模型承载能力。 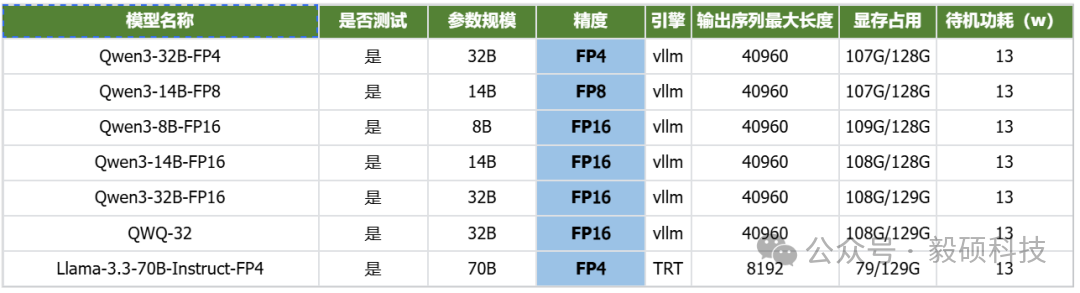 ## 2\. 并发测试 * 1个并发 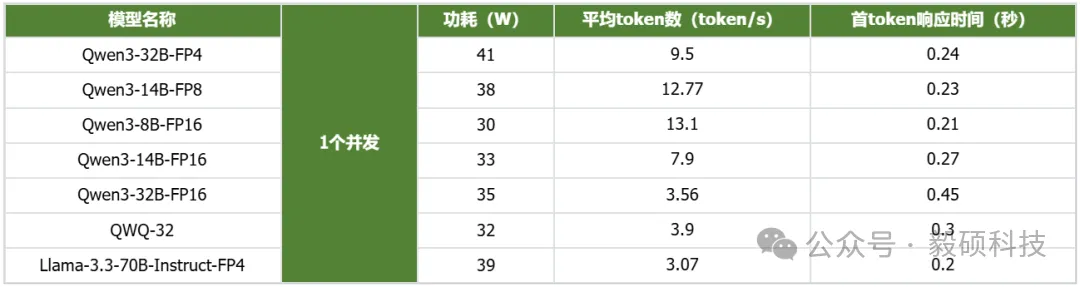 * 2个并发 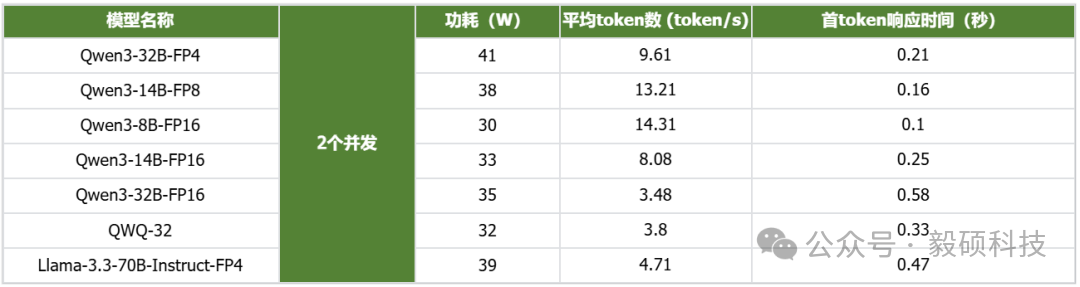 * 3个并发 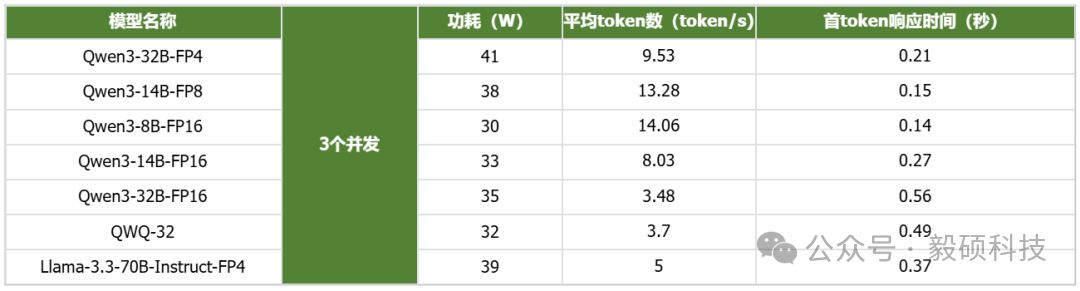 * 4个并发 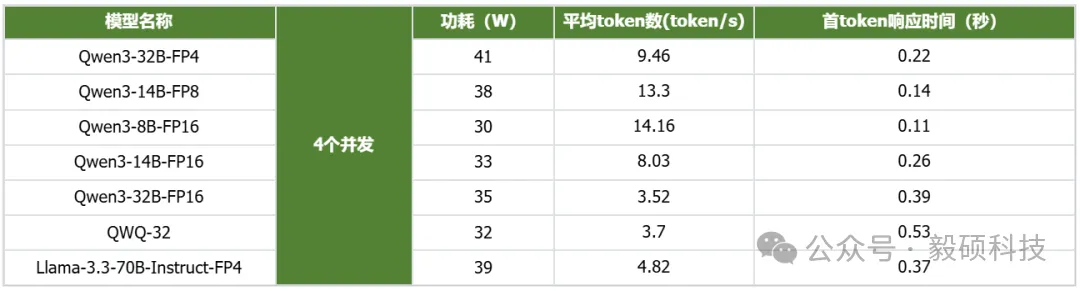 * 5个并发 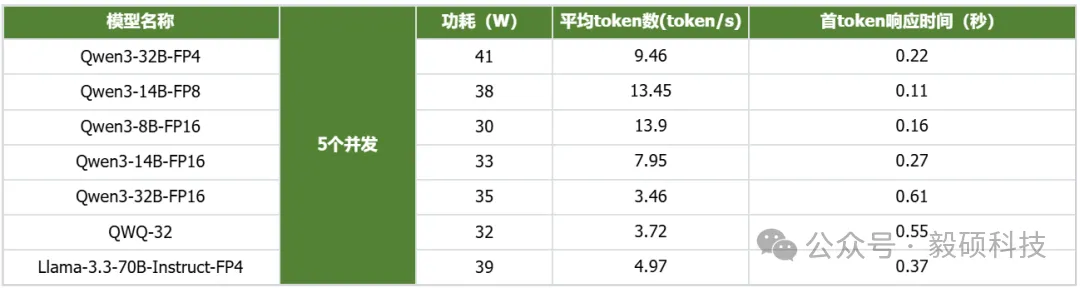 ## 3\. 测试页面 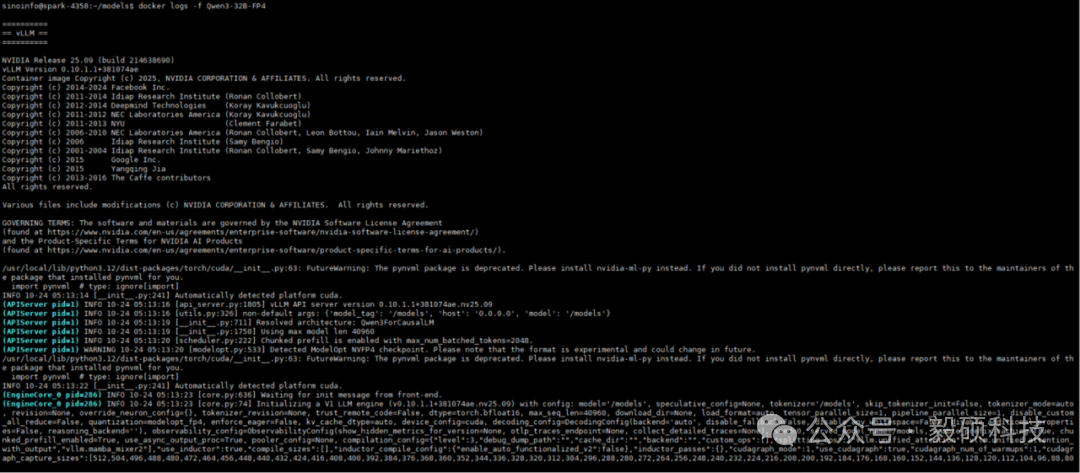 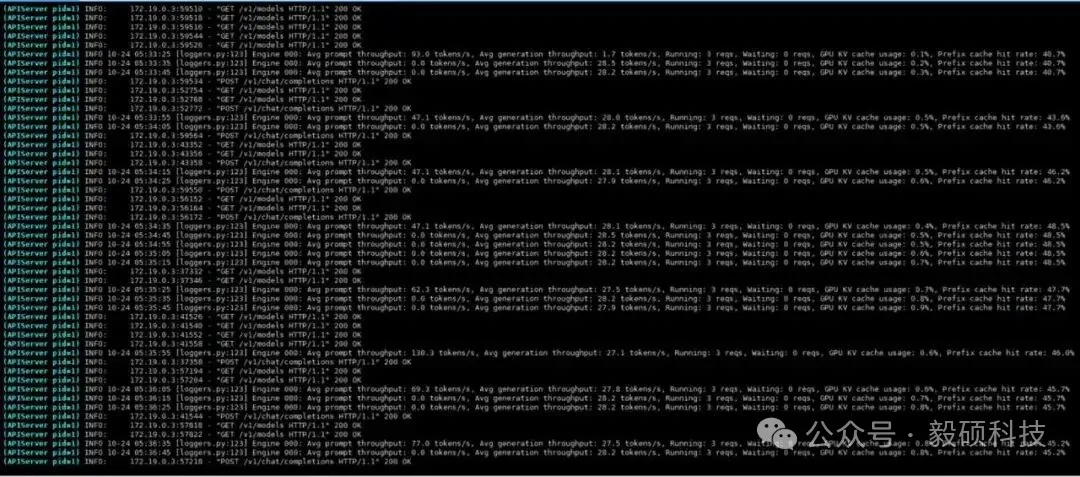 * * * # 六、大模型微调 ## 1\. 微调模型  ## 2\. 测试页面 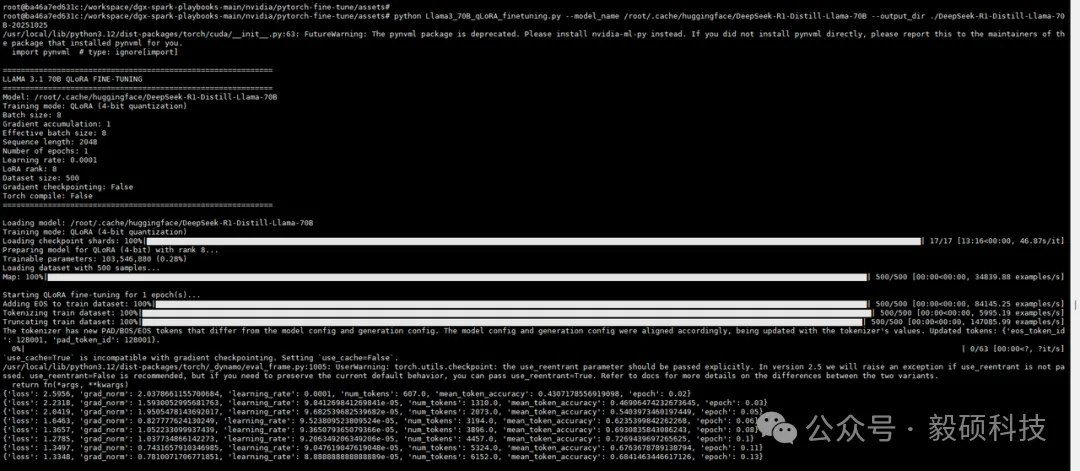 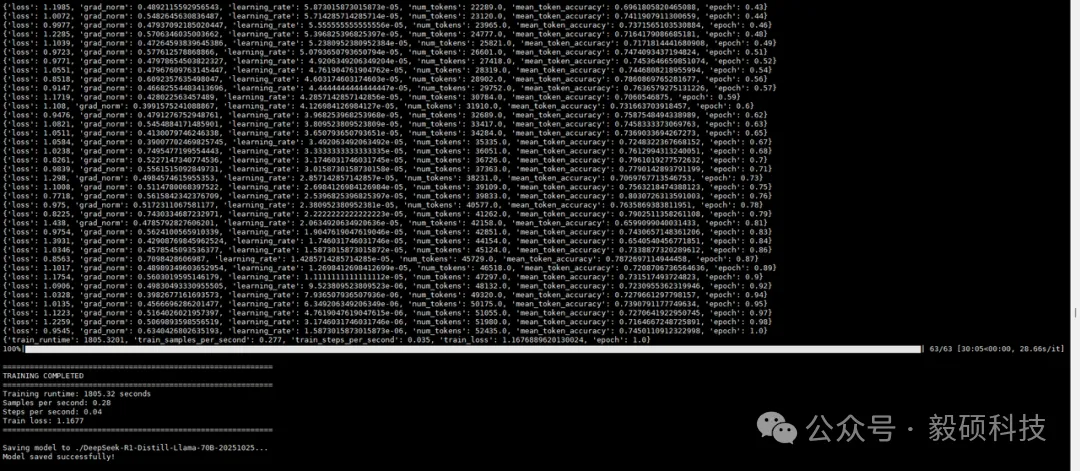 * * * # 七、MOE模型推理 ## 1\. 模型推理 * gpt-oss-20b 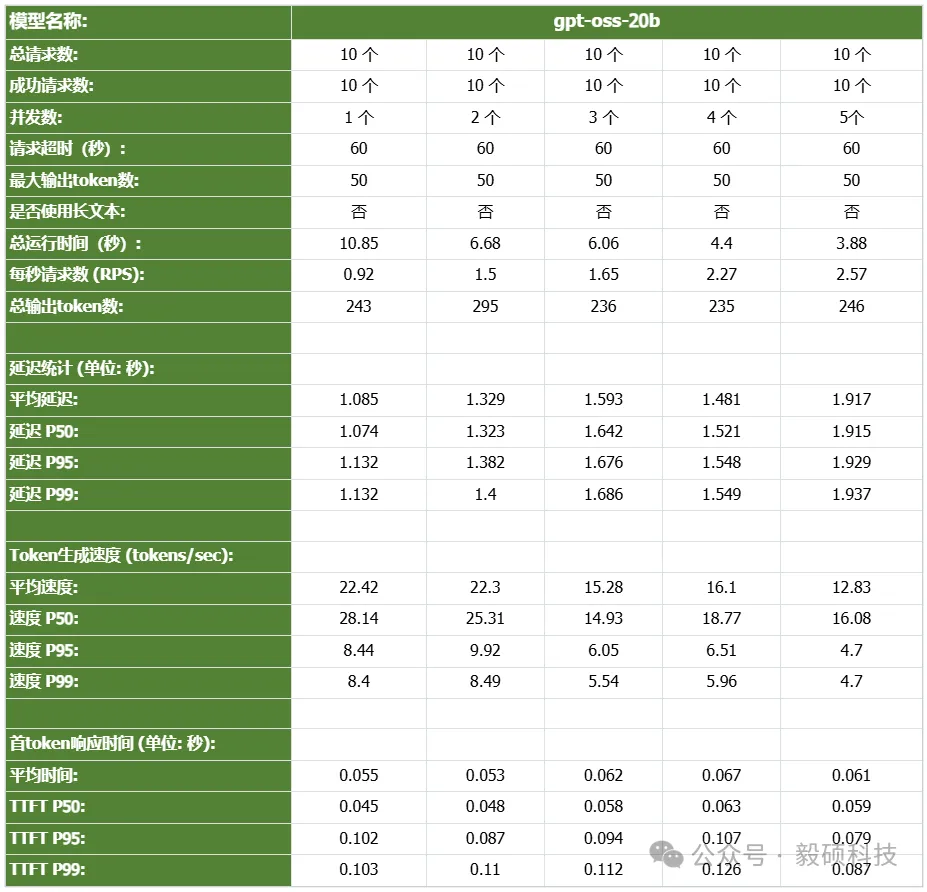 * Qwen3-30B-A3B-FP4 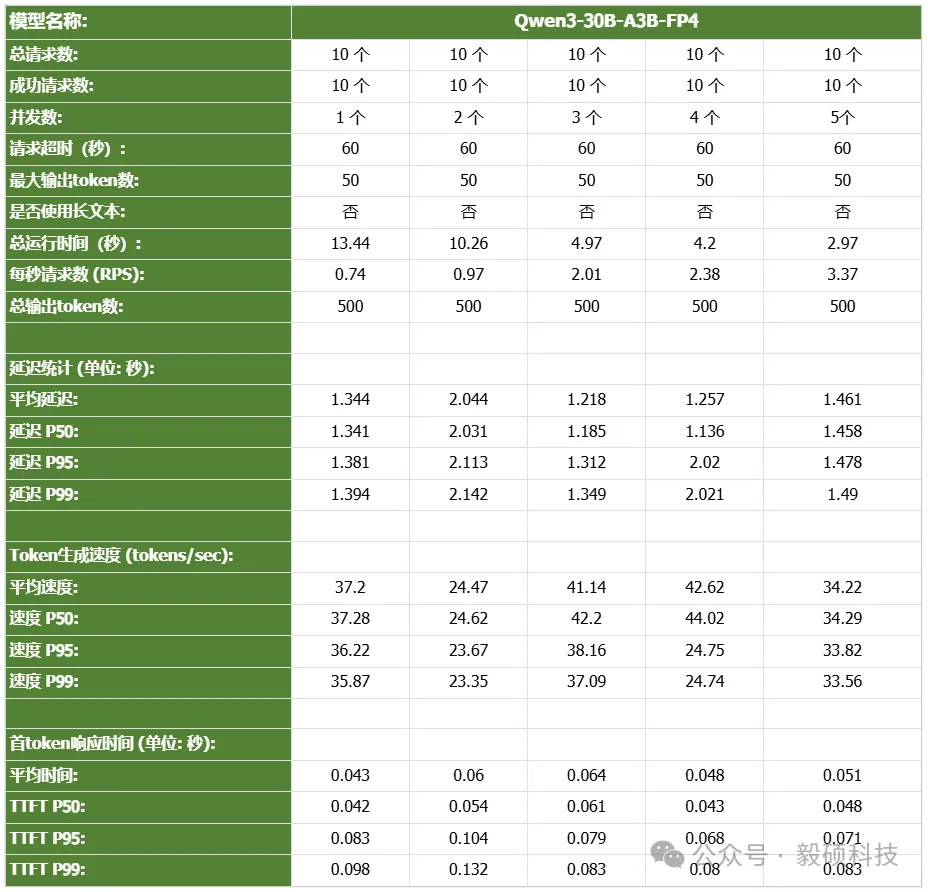 * gpt-oss-120b 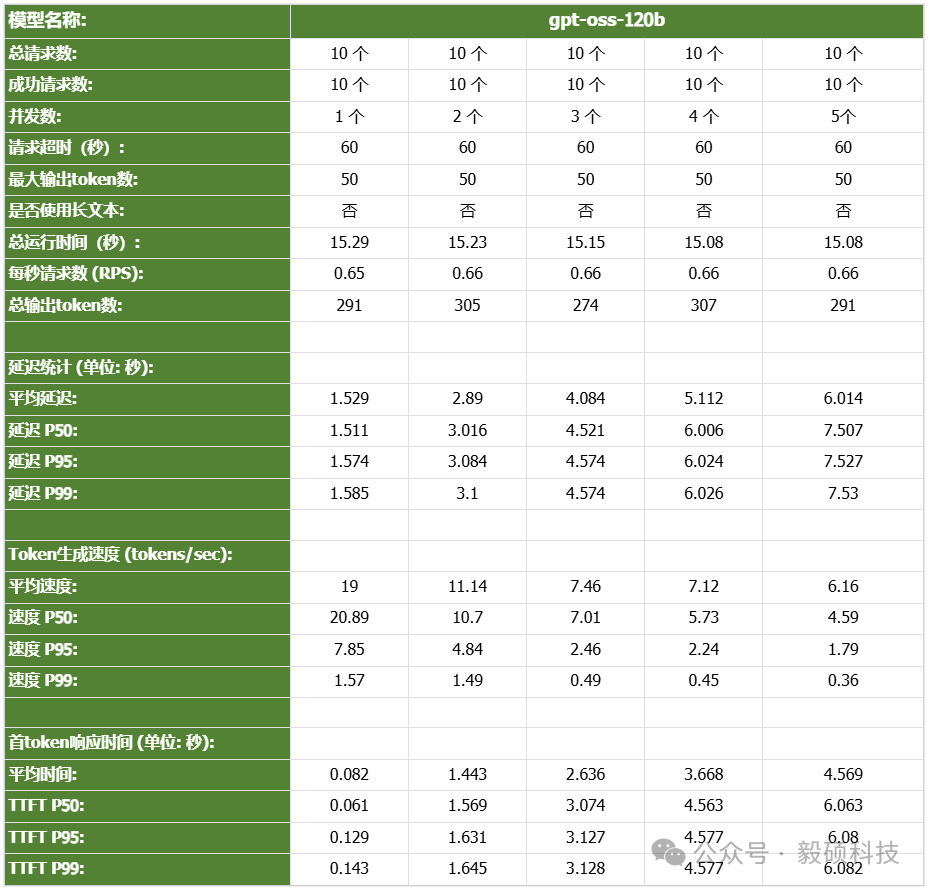 ## 2\. 测试页面    * * * # 八、测试结论 DGX Spark凭借其128GB统一共享内存,成功将Qwen3-32B-FP16等模型完整载入。这意味着,开发者终于可以在本地环境中,对那些过去只能在云端运行的大型模型进行功能验证、逻辑测试和效果评估。它解决了从0到1的问题,让模型能跑起来这是后续一切优化的前提。 在我们的实际体验中,从接通电源到成功运行第一个模型,整个过程流畅得令人惊讶。系统内置了经过优化的AI软件栈,你无需再为环境配置而分心。这种“开箱即用”的体验,带来的不仅仅是时间的节省,更是宝贵创作心流的保持。它让你从“运维工程师”的角色中解放出来,100%专注于你真正热爱的事情——编写代码、调试模型、探索AI的边界。同时,其极致的静音设计和本地化部署,确保了它是一个不打扰、绝对私密的工作伙伴。 * * * # 九、重塑您的 AI 工作流 NVIDIA DGX Spark 不仅仅是硬件的升级,更是开发范式的革新。它将数据中心的强大能力浓缩于 1.2 公斤的精致机身中,赋予了每一位 AI 探索者在本地掌控未来的能力。 无论您是探索最前沿算法的研究员,还是需要保障数据隐私的企业开发者,DGX Spark 都是您通往 AGI(通用人工智能)之路上最得力的伙伴。
chsnp
2026年1月28日 13:54
转发
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
Word文件
PDF文档
PDF文档(打印)
分享
链接
类型
密码
更新密码
有效期